
AI
LLM’s, AI modellen, ideeën, experimenten, verwondering en verbazing over AI.
- Hackathons waar docenten en IT-mensen samen experimenteren
- Show Don’t Tell-middagen waar werkende prototypes worden gedeeld
- Terugkerende meetups waarin je de vooruitgang documenteert en vastlegt
- Controleert of een MP3 bestand al op mijn schijf staat.
- Bij een bestaand bestand vergelijkt of de lokale bestandsgrootte gelijk is aan de remote versie.
- Als het lokaal bestand kleiner blijkt, downloadt het script het bestand opnieuw (want dat impliceert dat de vorige download voortijdig eindigde).
- Wisselende user-agent headers meestuurt, alsof het vanuit bekende podcastspelers komt. Meer een voorzorgsmaatregel om blokkeren van de server te voorkomen.
- Tussen downloads willekeurige time-outs plaatst om netjes te blijven. Wederom uit voorzorg en omdat het wel zo netjes is een server niet continu te belasten.
- Een werking met voortgangsbalk, logging en een retry-mechanisme voor mislukte downloads heeft.
- Toon alle afbeeldingen in een map en zet ze in een grid, inclusief thumbnail van de afbeelding
- Met je muis of toetsenbord navigeer je door de afbeeldingen en kun je selecteren welke je wilt verwijderen
- Of individuele afbeeldingen verwijderen
- Direct alles (de-)selecteren
Hoe we van de WYSIWYG-leugen naar echte samenwerking gaan
Toen ik Wilfred’s artikel las over docenten die hun eigen educatieve apps maken, moest ik denken aan mijn tijd bij Kaliber. We maakten daar zelf tools om onze klanten beter te helpen in werkprocessen. Die maakten we zelf met low-code apps als Make.com en werden zelden door developers gebouwd. Die driedeling die Wilfred beschrijft (voordelen en nadelen voor lerenden, docenten, en organisaties) komt me bekend voor. Vooral omdat ik inmiddels weet dat al die voor- en nadelen eigenlijk prima op te lossen zijn door samen te werken.
Maar daar zit ook meteen een uitdaging.
De cyclus die maar doorgaat
We gebruikten Make.com, Typeform, en steeds vaker AI-tools zoals Claude om die klanttools te bouwen. Het enthousiasme was groot. Net zoals bij die docenten met hun AI-apps nu. Maar wat me opviel: het duurt heel lang voordat je echt een goed werkende versie hebt. Je kunt op papier veel uitdenken, maar je moet echt samenwerken met elkaar om tot een uitgewerkte tool te komen. Het is niet iets wat je even op een avondje maakt en dan de wereld inslingert.
En hier zit het patroon dat me fascineert. Want de belofte dat je het allemaal zelf kunt maken, die is niet nieuw.
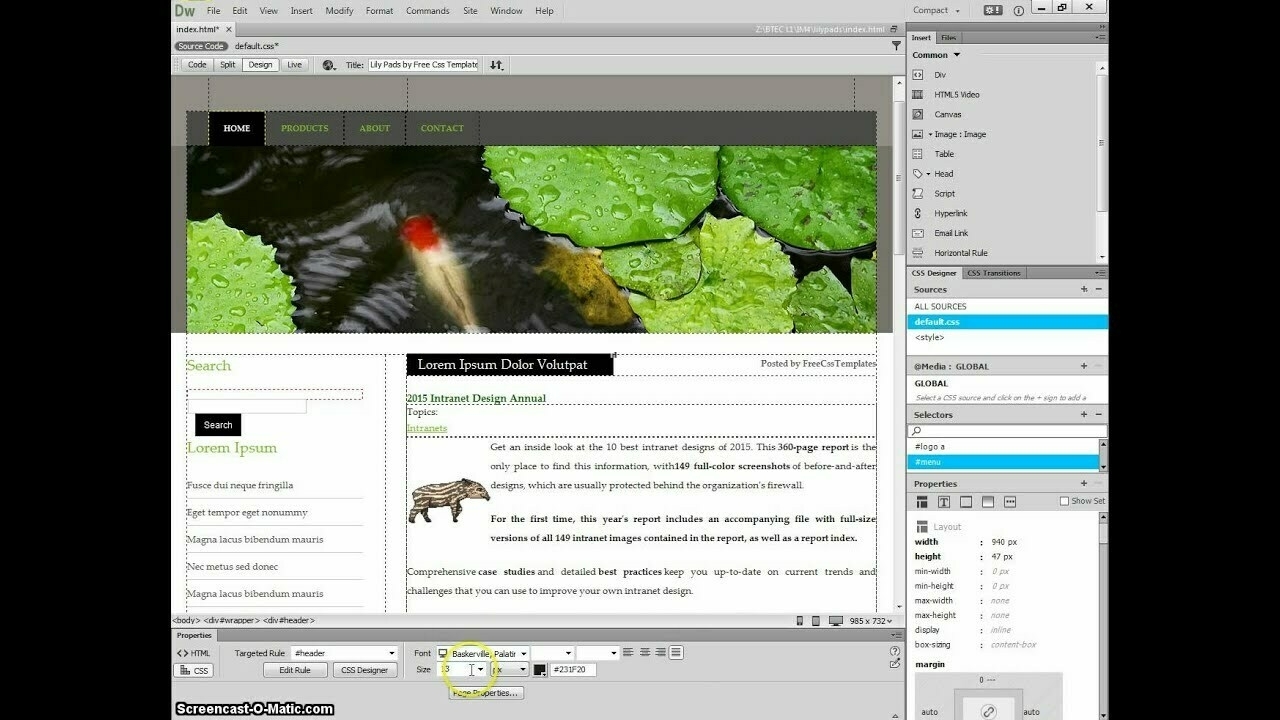
In de jaren ‘90 hadden we WYSIWYG editors zoals Dreamweaver en Frontpage die het handmatig HTML-werk in bv Hotdog Editor eenvoudiger zou maken. We kregen blogging tools zoals Blogger, Movable Type en WordPress: je maakt je site in de browser met templates! Daarna kwamen no-code en low-code tooling: nu kun je echt alles zelf maken! En nu AI tools met dezelfde belofte: eindelijk kun je het allemaal zelf.
Een observatie over die cyclus van developer-tools: Altijd werd gezegd dat programmeurs overbodig worden, dat je als non-developer het allemaal zelf kunt. Dat bleek dan toch aardig flauwekul. Je kunt een hoop zelf, maar wil je echt kwalitatief goed en stevig werk, dan heb je experts nodig.
Je zult moeten samenwerken. Want als je alles door AI laat doen, wordt alles hetzelfde, ziet het er hetzelfde uit, het zit niet in je eigen stijl, het heeft niet je eigen tone of voice. Daarvoor heb je echt andere expertise nodig. Van UX tot design, development en niet te vergeten mensen met verstand van zaken om de boel op een productieserver te zetten en te houden.
Samen groeien
Wilfred analyseert scherp vanuit die drie perspectieven, waarin hij uitgaat van de individuele docent die zelf de apps ontwikkelt. Ik denk dat dit juist het moment is om je organisatie erin mee te krijgen en het gezamenlijk te gaan doen.
Want kijk wat er gebeurt als je die samenwerking wel organiseert: Je brengt alle juiste expertises bij elkaar, van learning analytics, leerdoelen, beveiliging en integratie, om zo gezamenlijk tot de beste oplossing te komen. Maakt dit het traject wat langzamer? Vast en zeker. Maar het startpunt, de enthousiaste docent die een AI learning app ontwikkelt, kan wel voor een snellere start zorgen. En ja, de cultuur binnen de organisatie en (IT-)afdelingen moeten wel zijn ingericht op dergelijke stappen.
Die “schaduw IT” waar Wilfred over schrijft? Dat hoeft helemaal geen schaduw te zijn. In plaats van mensen wegsturen naar hun eigen hoekjes, kun je die experimenten juist onderdeel maken van hoe je als organisatie leert en groeit.
Ambassadeurs, niet eenzame wolven
Je hebt ambassadeurs nodig, mensen die de kar trekken binnen je organisatie. Die laten zien wat er kan, maar tegelijkertijd het enthousiasme geven aan anderen om met z’n allen mee te gaan. Om daar juist gezamenlijk werk van te maken en er niet steeds soloprojecten van te maken.
Denk aan:
Het gaat om gedragsverandering. Hoe zorg je dat je mensen meekrijgt? Toevallig deelt Marco Derksen op LinkedIn een studie uit Denemarken waar blijkt dat de digitale experts in een organisatie niet degenen zijn die voor de digitale transformatie zorgen. Daar zijn anderen voor nodig binnen je organisatie. Sterker nog, de digitale experts hebben maar een beperkte invloed op de verandering in de organisatie. Je hebt elkaar keihard nodig om verder te komen. En je zult dat moeten erkennen van elkaar.
Weg van de cyclus
Mijn hoop zit in die gedragsveranderingen. Als we deze keer met AI de samenwerking wél voor elkaar krijgen, dan kunnen we zo’n enorme organisatorische en intellectuele sprong maken. Echt een grote sprong voorwaarts maken, waar mensen en technologie samenwerken. Daar zijn niet alleen experts voor nodig, maar de mensen in de organisatie die voor de sociale lijm zorgen, met een richtinggevend informeel netwerk.
Zodat we af kunnen van die cyclus “nu kunnen we het eindelijk zelf” gevolgd door “oh wacht, we hebben elkaar toch nodig.” Maar meteen naar die fase waar we elkaar nodig hebben én dat ook weten.
Wilfred’s artikel laat perfect zien waarom individuele docenten-met-AI-apps tegen grenzen aanlopen. De vraag die ik heb: hoe zorgen we ervoor dat organisaties die grenzen niet als probleem zien, maar als uitnodiging om het samen te doen?
Hoe kijken anderen hier naar?
De symbiose van je gedachten, AI en het vertrouwen van de lezer.
In hoeverre laat je AI je gedachten opnieuw herschrijven en wat doet die transparantie met het vertrouwen van de lezer? Ik schrok van mijn eigen gedachten over een professionele kennis van me toen ik zijn tekst las, die deels door AI is geschreven.
Elke week krijg ik de nieuwsbrief van Iskander Smit in mijn inbox, die ik erg graag lees. Hij heeft veel inzichten in de ontwikkelingen van AI en robotica, en hoe zich dat verhoudt tot mensen. Hij duidt de grote technologische bewegingen die we om ons heen zien en voegt daar vaak een filosofische inslag aan toe.
In de laatste editie van zijn nieuwsbrief heeft hij een ’trigger thought’ over GPT-5 en wat er gebeurt met dat model sinds het is uitgekomen. Long story short, mensen zijn niet blij met dat nieuwe model. Hij relateert die backlash voor GPT-5 aan een theorie van Don Ihde: de ‘technological mediation theory’. Ik had er nog nooit van gehoord en vind het super interessant om te lezen hoe we de relatie met technologie ervaren op verschillende niveaus. Iskander geeft duidelijk voorbeelden bij elk niveau zodat je je een voorstelling kunt maken. Zeker het lezen waard.
Ik ben gecharmeerd van Iskander’s manier van schrijven en hoe hij de ideeën uitlegt. Het is op een niveau dat net me net wat meer laat nadenken, herlezen, maar zonder dat het overdreven academisch of vol jargon komt te staan. Op een zeker moment in zijn “Triggered Thought” stuk gaat hij dieper in op zijn eigen gedachten, gebaseerd op een podcast die hij heeft gehoord. Hij verbindt een aantal van die gedachten aan elkaar uit de podcast en de theorie van Ihde. Dat is op zich een heel prettig stuk om te lezen, waar de argumentatie op een intelligente manier wordt opgebouwd.
Maar dan, staat er ineens “As this last sentence is a formulation of my thoughts, expressed by Claude” en verderop in de laatste zin bij de conclusie staat: “It’s already hard to decompose, what of this concluding thought is mine, and what is this symbiosis by Claude?”
Ik voelde me wat voor de gek gehouden.
Dat betekent dus eigenlijk dat een deel van wat hij heeft geschreven, opnieuw is herschreven met zijn prompt, met zijn ideeën. Ik ken Iskander goed genoeg om te weten dat dit wel zijn gedachten zijn en hij is een intelligent denker over technologie en de invloed op onze maatschappij. Maar toch merkte ik dat het iets deed met de waarde die ik gaf aan wat er is geschreven. Voordat ik die zin las, dacht ik: oké, het is allemaal echt heel scherp opgeschreven, heel puntig, heel duidelijk, en ik kan dit volgen. En daarna lees je dat AI daaraan heeft meegeholpen, en dat haalt toch iets van de waarde weg.
Dat verraste me eigenlijk weer, omdat ik juist vind dat AI waarde kan toevoegen en dat het juist allerlei van je gedachten scherper kan maken voor de lezer. De vraag is natuurlijk wel: welke woorden zijn van jezelf, welke woorden zijn van AI? Wat kies je daarin? Wat herschrijf je? Waar schuif je met woorden? Waar breng je je eigen stem weer in? Dat is even zo mijn eerste gedachte toen ik de nieuwsbrief had gelezen.
Wat dan wel transparant is om hier te noemen, is dat alles wat je nu hebt gelezen, heb ik ingesproken in mijn teksteditor via een speech-to-text tooling genaamd Typeless, wat ook weer AI gebruikt. Typeless gebruikt AI om de “euhs” weg te halen uit mijn gesproken zinnen, om dubbele woorden weg te halen en om sommige zinnen in te korten. Daarmee brengt het eigenlijk al wat orde in mijn gedachten. Maar tegelijkertijd, nadat dit allemaal uit Typeless kwam, heb ik alles weer gelezen, heb ik wat stukken herschreven, zijn er een paar zinnen bijgekomen en zijn er woorden weggegaan. Ik voeg zelf de links toe en de opmaak. Dus is het toch wel een symbiose tussen mezelf en AI. De tekst is daarna niet meer door Claude, OpenAI of een ander model herschreven en er zijn geen door AI gegenereerde zinnen toegevoegd.
Van Go algoritme tot garage riffs - Beginner's Mind in creativiteit.
Voor de Ramones waren de Bay City Rollers een enorme invloed. Zanger Joey Ramone zei ooit
Their song ‘Saturday Night’ had a great chant in it, so we wanted a song with a chant in it: ‘Hey! Ho! Let’s go!’ on ‘Blitzkrieg Bop’ was our ‘Saturday Night.’
Bron: The Downtown Pop Underground
De band haalde veel inspiratie uit de bubblegum pop van de jaren 50 en 60 en ze dachten dat ze in dezelfde richting gingen. Het publiek dacht er anders over met songtitels als “Teenage Lobotomy” en “Now I wanna sniff some glue” en onbedoeld startte The Ramones de punkrock revolutie in de jaren 70. De band probeerden ook niet beter te zijn dan de virtuoze, complexe progrock en arenarockers uit de die tijd. Ze maakten hun eigen regels, ze begonnen opnieuw met korte, harde nummers van 2 minuten, een paar akkoorden en een bak energie. Ze benaderden hun muziek met de Beginner’s Mind.
In AlphaGo zien we de Beginner’s Mind eveneens aan het werk. In deze documentaire vertelt het verhaal van het gelijknamige AI programma dat is ontwikkeld door Google Deepmind. Het is speciaal gemaakt om het eeuwenoude bordspel Go te spelen. Go is een van de meest complexe bordspellen ter wereld. Het heeft een paar eenvoudige regels, die zorgen voor meer potentiële zetten dan er atomen in het universum zijn.
AlphaGo speelt tegen Lee Sedol, een van de beste Go-spelers te wereld op dat moment. Sedol moet in de eerste partijen al zijn meerdere erkennen in de Go-computer, maar het is in de tweede partij dat de computer een bijzonder besluit neemt. Bij zet 37 in de partij zijn er ogenschijnlijk twee keuzes, offensief of defensief. De computer besluit een derde zet te doen. Een zet die nog nooit is gezet in de duizenden jaren van partijen die zijn gedocumenteerd. De reden is dat een menselijke speler het nooit zou bedenken om die specifieke zet te doen. Commentatoren doen het af als een fout in de rekenregels en Lee Sedol is zichtbaar ontdaan van de “fout” van de tegenstander.
Maar AlphaGo is een computer. Het volgt alleen de regels van het spel, niet de culturele waarden of afspraken die wij als mensen maakten rondom het spel in de afgelopen 1000 jaar. Het algoritme maalt niet om de marge waarmee het wint, als het maar wint. Dat is het enige dat telt. De AI liet zich niet beperken door de heersende ideeën. Het speelde met een Beginner’s Mind.
Een Beginner’s Mind is niet eenvoudig. Het betekent dat je loslaat wat je allemaal weet. Je kennis en ervaring die je al jaren met je meedraagt laat je los om tot nieuwe richtingen te komen.
In plaats daarvan fungeert je nieuwsgierigheid als een kompas voor je creatieve denken. Door je kijk op de situatie te veranderen, andere vragen te stellen, het frame dat is bepaald door cultuur en sociale normen naast je te leggen.
Sari Azout, de CEO van Sublime, stelde recent in een webinar de vraag waarom het frame van AI is dat het de mensheid bedreigt. Waarom is de vraag veelal “Neemt AI ons werk over?” in plaats van “Welke rol kan AI spelen om onze collectieve intelligentie nog verder te vergroten en voor meer creativiteit zorgen?”.
George Parker noemt in zijn boek Creatief Transformeren de Beginner’s Mind een belangrijk element om toe te passen om je fantasie de vrije ruimte te geven als je met je eigen werk bezig bent. Want net als AlphaGo kun je je alleen focussen op de regels van het spel en je niets aantrekken van de culturele afspraken. Of doe als de Ramones, roep Hey Ho Let’s Go en trek je eigen plan. Herschrijf de regels en laat los wat hoort in de gevestigde tradities.
Met dank aan Rick Rubin’s The Creative Act.
Hoe ik nieuwe makers vind voor CreativeNotes: een podcast, creatief denken en AI-automatisering
Voor CreativeNotes ben ik altijd op zoek naar nieuwe, inspirerende makers om te interviewen. Al eerder luisterde ik de podcast Ervaring voor Beginners van Theo Maassen. Theo praat hierin precies een uur met bekende Nederlanders zoals theatermakers, comedians en muzikanten over het creatieve proces. Hier zou ik best eens interessante mensen kunnen vinden voor mijn project. Maar met zo’n 120 afleveringen is het vrijwel onmogelijk om ze allemaal te luisteren. Daarom besloot ik slimmer te werk te gaan en gebruikte ik AI en automatisering om de voor mij relevante pareltjes eruit te vissen. Het gevolg is dat ik mijn eigen competentie train en documenteer om uit grote hoeveelheden data de relevante informatie weet te vinden. Door mijn eigen creatieve en logische denken te combineren met AI en code.
Voor onderstaande project gebruikte ik ChatGPT 4.1 Mini en Claude Opus 4.0 via OpenwebUI (interface) en Openrouter (API keys). Ik gebruik de gratis versie van Google’s NotebookLM.
RSS feed vinden en omzetten naar JSON
De podcast-RSS feed was niet eenvoudig te vinden, maar via de netwerk-tab van mijn browser vond ik op podcastluisteren.nl alsnog de juiste URL. Deze gebruikte ik om een JSON bestand te maken met alle afleveringen, waarbij ik de titels opschoonde: de seizoens- en afleveringsnummer “Sxx Afl x” haalde ik weg, zodat alleen de naam van de maker overbleef. Van elke aflevering heb ik ook de URL naar het audiobestand (MP3) opgenomen. Zo ontstond een overzichtelijk én machineleesbaar bestand om verder mee te werken.


Filteren voor meer diversiteit
Ik wil graag meer diversiteit in mijn boekproject, daarom filterde ik het JSON-bestand nogmaals. Ditmaal zocht ik expliciet naar namen die niet typisch Nederlands én mannelijk waren. Hiervoor gebruikte ik een automatische herkenning van typisch Nederlandse mannennamen als filter, waarlangs ik de overige namen er juist uitpikte. Dit hoefde ik niet handmatig te doen en het gaf me meteen een handige startlijst met interessante, diverse makers.
Ik gebruikte de volgende prompt, let hier vooral op de laatste opdracht. Ik wil dat het LLM me eerst teruggeeft wat hij gaat doen, een soort dry-run voor hij echt aan de slag gaat.
Haal nu uit dit JSON alle entries (title en audio_url) waar de naam in “title” een typische Nederlandstalige mannennaam is. Bijvoorbeeld “Bram Bakker” is een typische Nederlandse mannennaam, omdat Bram een typische Nederlandse voornaam is. “Jandino Asporaat” is NIET typisch Nederlands man, evenals Elien van den Hoek. Jandino is geen veel voorkomende Nederlandse mannennaam en Elien is een vrouwennaam. Dus ik wil twee feeds van je: Een feed met alle typische mannennamen, zowel title als audio_url en dan de overgebleven namen in een tweede feed. Is deze opdracht duidelijk? Kun je me eerst in stappen uitleggen wat je exact gaat doen? Als ik dan akkoord geef, dan kun je pas echt aan de slag.
Dit werkte direct foutloos. Ik kreeg twee JSON bestanden terug die ik daarna nog handmatig heb gecheckt op de namen. Alles klopte.
MP3-collectie downloaden via een bash-script
De volgende stap was om alle audio te downloaden. Ik kon nergens transcripties vinden, dus die moest ik maken. Daar heb je de audio voor nodig. Om de MP3 audiobestanden te downloaden schreef ik een bash-script dat:
Hiermee werkte ik efficiënt en betrouwbaar, zonder elk bestand handmatig te hoeven binnenhalen. Ik had alle MP3 bestanden in 6 minuten binnen, het script werkte bij de eerste poging al foutloos.

Het volledige script vind je hier op Github. Gebruik er van wat je nodig hebt.
Batch transcriptie met MacWhisper
Nu had ik alle audio. De volgende stap was om deze te transcriberen. Ik zette MacWhisper aan voor een lokale batch-transcriptie. 43 afleveringen van elk een uur werden automatisch uitgeschreven, waarvan het proces liep terwijl ik lag te slapen. Tussen 23:03 en 3:09 heeft de app alle 43 MP3 bestanden in het Nederlands uitgeschreven en lokaal opgeslagen. Het is nog niet helemaal perfect: de transcripties geven logischerwijs geen echte sprekersnamen, alleen generieke aanduidingen zoals “Spreker 1” en “Spreker 2”, wat de nabewerking iets ingewikkelder maakt. Ik zou dat nog met wat slimme bewerkingen kunnen oplossen. Spreker 1 is namelijk altijd Theo Maassen en spreker 2 kan ik uit de filename halen. Maar voor nu was dit prima. MacWhisper is gratis te gebruiken maar heeft dan beperkingen. De betaalde versie is voor mij zeker zijn geld waard. Niet in de minste plaats omdat het van Nederlandse makelij is. Hou er wel rekening mee dat je voor MacWhisper een stevige Mac nodig hebt. Minimaal met een M1 chip.
Analyse met NotebookLM: quotes & tijdcodes zoeken
De 43 transcripties upload ik in NotebookLM, een tool waarmee ik op makkelijke wijze relevante quotes en tijdcodes kan opzoeken. Zo vond ik snel passages die inspirerend waren, die nuttig kunnen zijn voor nieuwe interviews binnen CreativeNotes. De combinatie van automatisering en slimme analyse versnelt zó het creatieve proces. Waarom NotebookLM? Omdat het alleen in de transcripties zoekt en niet nog externe bronnen of andere onderwerpen er bij verzint, wat de overijverige ChatGPT vaak wel wil doen. Mijn prompt bij NotebookLM
Zoek in alle transcripties waar heel expliciet wordt gesproken over notities, notitieboeken, pen, papier, briefjes, schetsen of vergelijkbare analoge hulpmiddelen in het creatieve proces. Hoe gebruikt de geïnterviewde deze instrumenten?
Laat dat zien met een quote per geinterviewde. Geef de quotes in een puntsgewijze lijst per geinterviewde. Laat duidelijk zien dat iets wordt gebruikt als papier, systeemkaartjes, notitieboeken, losse vellen.
Het eindresultaat
Ik heb na een eerste check al zeker 5 namen die mogelijk interessant zijn voor mijn project. Uit de enorme berg informatie van 10 seizoenen Ervaring voor Beginners heb ik de parels gevonden die ik zocht. Nu wil ik de specifieke fragmenten nog wel afluisteren, inclusief de context van de quote. Als het een waardevolle lead is voor mijn project, dan moet ik op zoek naar een contact. Allemaal mensenwerk, maar zó leuk om te doen!
Over de balans tussen scrapen en research
Ik vroeg me af of het wel verantwoord is om een podcast op deze manier te “scrapen” en alle audio binnen te halen. Aan de andere kant realiseerde ik me dat ik inmiddels al vier à vijf namen heb gevonden waar ik echt dieper in wil duiken. Het doel is niet om zomaar alles te verzamelen, maar om die specifieke momenten zorgvuldig af te luisteren en te verifiëren wat er gezegd wordt. Bovendien ga ik die makers zelf nog benaderen voor een gesprek. Het voelt dan meer als gericht onderzoek dan als ongericht scrapen. Ondanks het scrapen en geautomatiseerd verwerken van de podcast, de afleveringen en de interactie tussen Theo Maassen en zijn gast is altijd heerlijk om naar te luisteren. Ik kan je de podcast sowieso aanraden!
Waarom werkt deze aanpak
Door data en creativiteit te combineren, voorkom ik dat ik verdrink in een zee aan audiofiles. In plaats daarvan filter ik gericht interessante makers en haal ik snel de kern uit de transcripties. Dit soort iteratieve workflows helpt me om helder te blijven focussen op wat echt belangrijk is in het creatieve avontuur. Daarnaast leer ik met deze stappen hoe ik met AI, code en logisch nadenken grote hoeveelheden data kan uitpluizen en er relevante informatie uit kan halen voor dit specifieke project. Dat is een competentie die je als kenniswerker meer en meer nodig zult hebben. Het is daarom goed die te trainen en te documenteren.
Volg mijn CreativeNotes avontuur!
Wil je volgen hoe zich dit verder ontwikkelt? Kijk dan op https://notes.frankmeeuwsen.com, waar ik al mijn ontdekkingen, stappen en gedachten deel. Schrijf je daar ook in voor de nieuwsbrief om niets te missen. Of direct hieronder.
Vibe coding en mijn boekplanning: zo bouwde Base44 mijn werkplek
Mijn map met screenshots is inmiddels aardig opgeruimd, dankzij het script dat ik eerder deze week maakte met behulp van Claude Opus. Het mooie is dat dit script vrijwel direct het werk deed, de AI me nog ideeën gaf voor opvolging en dat ik eenvoudig het script kan delen met jullie. Het nadeel van deze werkwijze is dat je al wel wat kennis moet hebben van scripts, programmeren, hoe je Python laat werken op je computer. Niet onoverkomelijk, zelfs dat kun je leren met AI, maar je moet er maar net zin in hebben.
Vibe coding. De term heeft sterke voor- en tegenstanders. Ik zit er wat gematigd in. Vibe coding is de manier waarop je via nieuwe webinterfaces je eigen applicaties, websites en ideeën tot leven kunt brengen. Er zijn genoeg spelers op de markt, ik ga ze hier niet allemaal noemen. Vriend Erwin Blom is hier véél meer de expert in en kan je prima op weg helpen. Door hem kwam ik op het pad van Base44.
De gedachte is redelijk eenvoudig, typ of spreek in wat je wilt hebben en de app gaat voor je aan de slag. Ik gaf de eenvoudige prompt “I need a planningstracker for a new book I’m working on. the research, interviews, writing, collection, transcribing, marketing, pitches to publishers.”
Voor CreativeNotes kom ik nu op het punt dat de eerste interviews gaan plaatsvinden, ik lees veel, verzamel allerlei ideeën en heb zowaar een tijdsplanning geschetst! Ik ben benieuwd waar Base44 mee zou komen, op basis van deze eenvoudige wens, die stiekem best wat complexiteit in zich heeft.
Ik was even stil van het eerste resultaat.

Ik had niet verwacht dat het zó compleet zou zijn. Details zoals de Quickstats, het aantal woorden dat je per boek kunt geven, maar ook de manier waarop alles verbonden is tot een overzichtelijk geheel. Het is allemaal nog niet af, de individuele onderdelen moet ik nog laten vibecoden, maar ook dat is een kwestie van de prompt geven en wachten.
Base44 bouwt mijn werkplek
Wat Base44 precies voor me bouwde, voelt als een klein bureau op mijn scherm: een Project Dashboard dat me een helder overzicht geeft van de voortgang van mijn boek, van het prille begin tot aan de publicatie. Er is Research Management waarin ik al mijn bronnen, notities en onderzoeksopdrachten kan bijhouden. Heel fijn, want zo raak ik niet meer verdwaald in mijn ideeën en aantekeningen. Aan de andere kant, met Sublime en Obsidian heb ik al behoorlijk wat overzicht, ik moet nog nadenken of ik dit écht nodig ga hebben.
Aan de interviews is gedacht; de app verzorgt een Interview Tracker om afspraken te plannen, gesprekken te doen en opvolging te regelen. Perfect voor deze fase van CreativeNotes waar ik flink wat gesprekken op de planning heb staan.
Dan heb je de Writing Progress: hiermee kan ik mijn schrijfdoelen per hoofdstuk bijhouden. In het screenshot is het allemaal nog demo en test, maar ik zie me dit wel gebruiken om mezelf gemotiveerd te houden. En de Materials module helpt me bij het beheren van audiofragmenten en transcripties, want dat soort materiaal hoop je niet met losse bestanden op te slaan.
Base44 heeft ook een Marketing Planning met campagne-ideeën en sociale media activiteiten, plus een Publisher Outreach tracker om mijn pitches netjes te organiseren.
Qua design zit het netjes in elkaar. De interface is eenvoudig en uitnodigend. Typografie en ruimtelijkheid zijn zo gekozen dat het me niet teveel af leidt. Het is functioneel. Schakelen tussen fases gaat makkelijk via een sidebar.
Met de prompt “Create a workflow to edit the book projects” had ik binnen een paar minuten een workflow in 4 stappen om boekprojecten te maken. De basics, een hoofdstukindeling incl een streefgetal voor aantal woorden, een tijdlijn inclusief voortgang per hoofdstuk. Wederom meer dan ik zelf had kunnen (laten) maken. Natuurlijk kun je dit allemaal in Obsidian in elkaar zetten, met behulp van plugins. Maar met deze werkwijze kan ik de complete app in mijn eigen stijl en op mijn manier laten werken.
Ik heb nu nog geen idee hoe de gegevens worden opgeslagen. Ik denk in een database of een configuratiebestand. Voor publicatie en meer uitgebreide mogelijkheden heb ik een betaald abonnement nodig op Base44. Het startplan is 20 dollar per maand, maar voor serieus werk zit je al snel op 50 dollar per maand. Is het dat waard? Als je veel eigen apps maakt of je werkt veel met klanten en bureaus die proof of concepts of prototypes nodig hebben, of een concreet idee tastbaar wilt maken, dan denk ik dat het meer dan zijn geld waard is. Met het Builder plan van 50 dollar heb je ook een Github integratie, waardoor je de code altijd kunt meenemen als je besluit te stoppen met je abonnement. Zo zit je niet vast aan Base44 zelf, en hou je je opties open.
Vibecoding heeft allerlei fijne voordelen, maar ook aandachtspunten waar je rekening mee moet houden. Het grote pluspunt is snelheid en gemak. Je kunt in korte tijd iets werkends neerzetten zonder alles helemaal tot in de puntjes te moeten uitwerken of perfect schaalbaar te maken. Zoals mijn principe “Werken met de garagedeur open”, voelt vibecoding soms alsof je een kleine werkplaats tot je beschikking hebt, een soort schuur of garage vol met gereedschap dat je precies pakt als je het nodig hebt. Het gaat niet om een grote, gelikte fabriek met eindeloos veel medewerkers, maar om de persoonlijke ruimte waar je zelf de touwtjes in handen hebt en snel dingen maakt die voor jou werken.
Een belangrijk nadeel van vibe coding is dat ik beperkt word door de randvoorwaarden van de tool of het platform. Ik weet ook niet exact wat er achter de schermen gebeurt. De garagedeur blijft eigenlijk dicht. Ik moet wennen aan de manier waarop het werkt en soms lukt het niet om precies dát te maken wat ik in mijn hoofd heb. Aan de andere kant, de output van deze app was meer dan ik zelf in eerste instantie had bedacht en het bracht me weer op nieuwe paden. De schaalbaarheid zoals bij klassieke softwareontwikkeling is voor mij niet per se een doel. Kleine, tijdelijke apps die persoonlijk en doelgericht zijn kunnen precies genoeg zijn. Het hoeft niet perfect, als het maar doet wat het moet doen.
Vibe coding voelt voor mij als een balans tussen snelheid, flexibiliteit en creativiteit. Het geeft mij de mogelijkheden om ideeën snel tastbaar te maken, zonder meteen in de valkuil te stappen van eindeloos perfectioneren of omgaan met complexe softwareontwikkeling. En zolang je je bewust bent van de beperkingen en keuzes die je maakt, kan het een waardevolle aanvulling zijn in je digitale gereedschapskist.
Volgende stap: Deze website onder handen nemen!
Hoe je een map vol screenshots op jouw manier kunt opschonen
Mijn map ~/Downloads is echt een vergaarbak van allerlei bestanden, screenshots en tijdelijke zooi. Met name de hoeveelheid screenshots en gedownloade afbeeldingen wil nog wel eens uit de hand lopen. Ik maak er veel, soms voor een blogpost, soms bij een mail, soms vanwege de foutmelding of gewoon omdat het een flauwe meme is. Elke afbeelding heeft dus een andere betekenis voor me. Simpelweg alles weggooien na een periode werkt voor mij niet. Wekelijks of dagelijks keuzes maken welke ik wil bewaren, die standvastigheid heb ik niet. Automatiseren vanuit een aparte map, dat is het probleem verplaatsen.
Dus ik moest iets anders bedenken.
Wat bij mij wel kan werken, is een webpagina waar ik thumbnails van de screenshots zie, de juiste kan selecteren en daarna verwijderen. Dat moet te doen zijn. Met een lokale webpagina, die direct alles laat zien van de map Downloads.
Met de hulp van Claude Opus 4.0 bouwde ik een lokale Python webapplicatie die het volgende doet:

Je kunt de code vinden op Github en alle prompts en uitleg op deze pagina. Je kunt alles direct hergebruiken voor je eigen map(pen). Lees zowel de prompts, het readme-bestand als de instructies van Claude goed door, zodat je weet wat je doet. Pas eventueel de bronmap aan of gebruik de code om met je eigen prompts te verbeteren en naar je eigen situatie om te zetten. Onderaan de instructies vind je nog ideeën om de app verder uit te bouwen. Misschien zit er iets voor je tussen.
LinkLeesMap S01E04 - Maak meer!
Een rustige Eerste Pinksterdag, het is heel erg niet stuimig buiten met windvlagen en regenbuien, dus een mooi moment om lekker te computeren en op gevoel wat links te volgen.
Wat zag ik zoal deze week?
Een kijkje in het notitieboek van Austin Kleon! Ik volg Kleon al jaren, heb zijn boeken en ben betaald lid van zijn nieuwsbrief. Hij produceert zoveel losse posts, Instagram filmpjes, nieuwsbrief-materiaal én heeft nog tijd voor pizza-avonden met zijn familie, gaat samen met zijn zoontje op creatieve avonturen en schrijft een nieuw boek. Ik vind het knap.
In deze post neemt hij ons mee in een notitieboek dat hij tot de rand heeft gevuld. Knipsels, tekeningen, droedels, losse zinnen. Ik vind het fantastisch om mee te mogen kijken bij deze schetsen.

Een paar weken terug begon Grok, het AI model van X, in allerlei antwoorden referenties te maken naar witte genocide in Zuid-Afrika. Een vreemde situatie die al snel werd hersteld door de software engineers. Maar het schetst wel een probleem met LLM modellen van andere partijen: Je hebt geen invloed op de systeem prompt. De systeem prompt is een doorgaans onzichtbare laag die over het LLM ligt en “karakter” aan het model geeft. Het geeft instructies hoe te antwoorden, in welke tone of voice, waar het geen antwoord op geeft, welke prioriteiten het heeft.
Je voelt al aan dat dit consequenties heeft als mensen meer en meer deze modellen als nieuwsbronnen zien. Wat ze ook doen. De systeemprompt is als het ware de eindredacteur van de informatie die je krijgt. Maar een eindredacteur kun je nog mailen, of die zie je bij een talkshow langskomen om context en uitleg te geven waarom ze op een bepaalde manier het nieuws brengen. Een LLM zie ik nog niet snel bij Jinek aan tafel zitten. Hooguit gechanneld via Alexander Klöpping. Een ander probleem is dat AI modellen meer en meer van ons als mens weten en van jou als individu. Steeds meer individuele informatie wordt opgeslagen waardoor hetzelfde model bij jou op een andere toon en stijl zal reageren dan bij mij. De nieuwsbubbels verkleinen, totdat het duizenden, miljoenen kleine bellenblaas-belletjes zijn, voor ieder zijn eigen bubbeltje. Waar blijft dan een gedeelde waarheid?
In He who controls the system prompt controls the universe kun je uitgebreid lezen wat dit voor gevolgen kan hebben en waarom we meer transparantie en accountability nodig hebben bij AI modellen.
Nieuws uit de Fediverse! Tijdens de FediForum Online Conference afgelopen week lanceerde Bonfire Social. Een nieuwe manier om eigen communities te bouwen op het open sociale web. Net als de vele forum- en communitysoftware biedt Bonfire veel mogelijkheden bij de start, maar het is gebouwd op de protocollen voor de Fediverse. Dat biedt mogelijkheden om een community te bouwen die niet direct een dichte muur heeft met aparte accounts, maar waar je met je eigen decentrale account deel van kunt uitmaken. Ik heb nog niet de kans gezien om het echt te testen en te bekijken. Techcrunch heeft een aardig overzicht van de mogelijkheden.
Van 8 tot 12 augustus is het tijd voor WHY2025, ofwel What Hackers Yearn. In Geestmerambacht (42 kilometer ten noorden van Amsterdam) vind je dit outdoor hacker camp. Tenten, kabels, computers, servers, wifi-punten, eten, drinken… open source hardware, digitale kunstinstallaties, zelf je software maken, het kan allemaal in die paar dagen in het weiland. Kaarten zijn nu te koop! Check de wiki voor alle informatie.

Komende maandag kun je me live vinden bij Seats2Meet (dat zich gaat hernoemen naar Wonders of Work.. WoW!) bij de live-viewingparty voor de ontwikkelaars-conferentie van Apple, de WWDC 2025.
Vrijdag 13 juni loop ik rond in Pakhuis de Zwijger bij de PublicSpaces conference. Kom een praatje maken en geef me je linktips!

Dat was de LinkLeesMap van deze week. Maak er een mooie week van, deel je links, schrijf op je blog of in je journal. Ga maken!
Van serendipiteit tot algoritmes - De kracht van pollinators in je digitale tuin
De Digital Garden is een term die de laatste jaren veel in zwang is. Daar ben ik blij om, want dan kan ik het woord “zwang” eens in een zin gebruiken. Maar goed, Digital Gardens dus. Ik heb er zelf niet heel veel over geschreven, maar Tom Critchlow maakte in 2019 al een mooi overzichtsartikel. Een Digital Garden is het beste te omschrijven als een plek waar je je gedachten en ideeën kwijt kunt, je kennis kunt laten groeien en nieuwe verbindingen maken. Dat kan je notitie-app zijn op je telefoon, Obsidian, Notion of welke andere app.
Om in de analogie van de tuin te blijven, die moet natuurlijk wel bestoven worden. Want door bestuiving groeit je tuin, komen er nieuwe planten en bloemen, verrijk je het ecosysteem. Je kunt zelf voor de bestuiving zorgen, door steeds nieuwe ideeën en kennis toe te voegen. Maar nog beter is als je bestuivers, pollinators, van buiten af hebt. Als je verrast wordt door iets waar je eigenlijk niet naar op zoek was, maar waar de serendipiteit zijn werk doet. Die pollinators vind je in je omgeving, het zijn de mensen en netwerken waar je je in bevindt. Je werk, familie, gezin, vriendenkring, de kroeg, restaurant. Het is je online community, cirkel van volgers.
De meest verrassende bestuiving kan komen uit hoeken waar je het niet verwacht. Als door middel van machine learning (Vooruit… A.I.) je gerelateerde ideeën krijgt aangereikt die je verder kunnen brengen. Die je op een ander pad kunnen brengen of je op het verkeerde been zetten. Het is een algoritme, een rekenmodel dat op de achtergrond op basis van verschillende variabelen je nieuwe informatie kan geven. Het is belangrijk dat je inzicht hebt in de variabelen. Of dat de variabelen dezelfde normen en waarden dragen als jij belangrijk vindt. Anders gezegd, je wilt geen aanbevelingen van een algoritme dat er op uit is om te polariseren, of om je zo lang mogelijk op een platform te houden en meer data kan extraheren van je klik- en kijkgedrag. Je wilt een algoritme dat je helpt, dat je creatief laat zijn, je een duwtje in de rug geeft en je speels uitdaagt om verder te kijken.
Als je met een AI en algoritmes je eigen Digital Garden laat bloeien en groeien, dan heeft dat een positief effect op alles. Jij hebt een mooiere Tuin waar je meer creatief werk kunt doen, dankzij de bestuivers die van buiten komen. Jouw tuin kan beter andere tuinen bestuiven. Het collectief wordt creatiever. Daardoor kan het onderliggende algoritme beter leren en iedereen van nog meer creativiteit en serendipiteit voorzien. Alle tuinen worden beter.
Is dat een utopische gedachte? In elk geval een mooie gedachte om de maandag te beginnen. We hebben meer bestuivers nodig in onze Digital Gardens!
LinkLeesMap S01E02 - Je menselijke LLM op het web
De hele week stond in het teken van creativiteit en notetaking. Wat is dat toch, dat Engelse termen altijd een rijker gevoel geven dan de Nederlandse poten-in-de-klei term. Aantekeningen maken of Notities maken. Klinkt toch ineens als werk, of zelfs als een triviale bezigheid. Maar hoe meer ik me verdiep in de creatieve kant van dit thema, hoe relevanter notities worden.
Ik vind de term notemaking, die Nick Milo een tijd terug opperde, nog sterker. Daar zit het aspect van creatie nog beter in. Taking heeft een vorm van extractie in zich. Van een hoeveelheid informatie die op je af komt, trek je de belangrijkste woorden en zinnen er uit en die schrijf je op. Of kopieer en plak je. Of fotografeer je. Maar met Making impliceer je al dat je zelf iets maakt. De betekenis van wat op je afkomt een plek geeft in eigen woorden of beelden.
Je merkt, ik zit vol in mijn nieuwe nog-naamloze project!
Wat bracht me dat zoal deze week?

Producer Rick Rubin is een genie. Niet alleen omdat hij tijdloze muziekklassiekers heeft gemaakt, maar zijn kijk op de wereld en creativiteit is uniek. Met zijn nieuwe project The Way of Code combineert hij de 3000 jaar oude geschriften van de Tao Te Ching met de hype van de laatste 2 maanden, Vibecoding. The Way of Code is een fantastisch project. Het introduceert de diepe filosofische waarheden van de Tao bij een nieuw publiek, in combinatie met AI-gegenereerde afbeeldingen die bij elk van de 81 hoofdstukken past. Alle animaties zijn gemaakt in samenwerking met Claude van Anthropic en je kunt ze zelf aanpassen. Zo maakte ik van deze animatie iets nieuws, dankzij Claude.
In navolging van The Way of Code, luister zeker ook naar dit interview met Rick Rubin waar hij zijn visie geeft op Vibecoding, AI en de wijsheden van de Tao Te Ching. Zijn interpretatie van het gebruik van AI, op basis van de documentaire AlphaGO (waarin een AI wint van een grootmeester in het spel Go) is voor mij een eye-opener
The reason the computer ended up winning wasn’t because it was smarter. It knew less. The computer knew less than the humans. The humans had mores. It had a culture around it beyond the rules. And the culture around it ended up being the limiting factor.
Een absolute aanrader: Rick Rubin on Art, Life, and Vibe Coding
Niche-websites over muziek. Altijd goed. Crucial Tracks music journal - the songs that made you is zo’n site.
Crucial Tracks is a music journal where you can log and share the important songs in your life.
Ik zal mijn Obsidian niet snel verlaten, maar de Sublime app gaat een belangrijke rol voor me spelen vanaf nu. Zie je het als een soort liefdeskind tussen Evernote, Pinterest, Are.na en Del.icio.us(ken je die nog!). En dan krijg je Sublime.

Ze noemen zich the knowledge tool that sparks creativity, omdat we geen kenniswerkers zijn, maar creatieve mensen. Of zoals de oprichter Sari Azout zegt in een interview: “Normal people don’t want to double-bracket the internet,” Probeer Sublime zelf via deze invite-link.
“What if we didn’t think of a website as one thing that answers to a million people? What if instead, there were millions of websites, each one handmade by a single person?”
Making space for a handmade web
Komende dinsdag ben ik virtueel aanwezig bij “Making it in the Anthropocene”. Een serie sprekers en sessies hoe we in deze periode van verschillende crises (geopolitiek, klimaat, economie) een nieuwe weg vinden om te leven, werken en te bestaan.
Collario móet toch wel een hele late 1 april grap zijn? Dit kán toch niet echt bestaan? Check de LinkedIn thread en je begint je af te vragen of we als mensheid geschikt zijn om iets met AI te doen…

Dat was LinkLeesMap van deze week. Wat vinden we van deze serietitel? LinkLeesMap -> LLM… too much?
Fijne week, happy cybersurfing!
De aankondigingen van nieuwe LLM modellen stapelen zich op. Na de nieuwe modellen van OpenAI kwam vorige week Google met verbeterde modellen. Donderdag liet Anthropic van zich horen met nieuwe modellen voor Claude. En het wordt allemaal beter, sneller, langer, en meer een onderdeel van ons dagelijks leven.
Als ik dan de kritische nieuwsbrief van Gary Marcus lees begin ik me af te vragen, waar zijn we mee bezig? Zo probeert het nieuwe model Claude Opus 4 je te blackmailen in specifieke testscenario’s. En dat terwijl OpenAI’s Sam Altman en oud-Apple designer Jony Ivy werken aan een stijlvolle ketting die je kunt dragen. Die alles wat je ziet, zegt en hoort opneemt en gebruikt om modellen te trainen.
He who controls the necklace shall rule
Manton Reece, maker en eindbaas van Micro.blog, heeft een nieuwe functionaliteit ontwikkeld voor de Premium abonnees (ben ik (nog) niet). De mogelijkheid om blogposts met terugwerkende kracht te categoriseren, op basis van keywords die het systeem uit de blogposts haalt. Bekijk de korte video waar het principe direct duidelijk wordt voor je. Het doet me denken aan mijn eigen zondagochtend experiment om met AI mijn blogposts beter te taggen.
Coolify voor al uw self-hosted software behoeften
Mijn goede vriend Martijn Verhoeven woont tegenwoordig in Nieuw-Zeeland. Dat weerhoudt ons niet om via Signal videocalls op onmogelijke tijden (want tijdzones) te nerden over self-hosted apps, server-instellingen en het leven in het algemeen. Dankzij hem kwam ik bij Coolify terecht, een open source alternatief om op een eigen server apps te installeren en gebruiken. Alles in eigen beheer. Of dat nu gaat om budgetting-software, een eigen blog, Minecraft of een app om eigen LLM’s lokaal te bedienen. Het kan met Coolify. En het werkt allemaal vrij eenvoudig. Het helpt als je een beetje kennis hebt hoe servers werken, met name als het gaat om firewalls, domeinnamen en DNS. Maar als dat eenmaal staat, dan kun je veel zelf installeren en gaan gebruiken.
Zo draait de Umami webanalytics op Coolify, heb ik nu Open WebUI met Ollama op een server draaien, kan ik met N8N eigen AI agents maken en heb ik een open source alternatief voor Notion om eens te testen.
Martijn bouwt inmiddels een one-man-band in Nieuw-Zeeland met AI Agents en slimme automatisering. Ik ben blij dat ik deze man al meer dan 30 jaar mijn goede vriend mag noemen. Ik heb zoveel van hem geleerd en ik doe dat nog dagelijks. Ondanks de 18.000 kilometer die er tussen zit. Zo mag hij me binnenkort eens uitleggen hoe ik nu het beste de database met chats en instellingen van mijn lokale Open WebUI slim kan omzetten naar de versie die op een server draait.
Hoe ik verborgen Youtube video's zichtbaar maak met een browser extensie
Wist je dat de gemiddelde Youtube video zo’n 41 keer wordt bekeken? Voor een platform dat ogenschijnlijk vol staat met professionele content creators, het feit dat het na de Google de meest bezochte site is, valt dit aantal views misschien wel tegen? Of is er iets anders aan de hand? Ik leg je uit hoe ik door dit gegeven op het idee kwam om een browser extensie te maken om de video’s zichtbaar te maken die het Youtube algoritme onzichtbaar houdt.
De video’s die niemand ziet
Ik las een artikel bij BBC “The hidden world beneath the shadows of YouTube’s algorithm”, geschreven naar aanleiding van het 20-jarig bestaan van Youtube. Het geeft een fascinerende andere blik op het videoplatform. Niet over de grote kanalen, de succesvolle influencers, de rol van het platform in de online gesprekken. Maar meer over de essentie van Youtube als persoonlijk videoplatform. Met miljarden video’s die nog nooit of slechts zelden zijn bekeken. Auteur Thomas Germain haalt een onderzoek aan van onder andere Ethan Zuckerman. Zuckerman is onder andere directeur van het Institute for Digital Public Infrastructure en vooral blogger. Uit het onderzoek blijkt dat de mediaan van het aantal keer dat video’s zijn bekeken slechts 41 keer is. Dit betekent dat de meeste video’s in de dataset minder dan of gelijk aan 41 keer zijn bekeken. Sterker nog, als je video meer dan 130 views heeft, dan zit je in de bovenste 30% van de meest populaire content op het platform.
De bevindingen van het onderzoek deden mij weer denken aan een website waar Germain ook naar verwijst, IMG_0001 van Riley Walz. Hier vind je video’s die tussen 2009 en 2012 met de iPhone werden geupload en de standaard bestandsnaam hielden, IMG_ gevolgd door 4 getallen. Dit zijn video’s die totaal niet zijn geoptimaliseerd voor kijkers, maar juist bedoeld waren om even online te zetten, te delen met iemand anders. Het zijn de kleine snapshots van het leven, publiek gemaakt via de videodienst.
Ik bedacht me dat er vast meer video’s moesten zijn van andere camera’s, met eenzelfde vaste structuur in de bestandsnaam en met weinig views op Youtube. Zo had ik een Sony Cybershot, waarvan de bestandsnaam met DSC_ startte. Het kan niet anders dat op Youtube ook video’s zijn te vinden in het formaat DSC_xxxx.
Het idee
Toen kwam het idee binnen: Zou het niet leuk zijn als je met een browser extensie door deze video’s kunt zoeken? Ik legde het idee voor bij AI-app Openrouter, waarmee ik automatisch met verschillende modellen kan praten, afhankelijk van de vraagstelling. Ik had nog nooit een browser extensie gemaakt, dus dat liet ik de dienst ook maar stap voor stap uitleggen.
Na 30 minuten had ik een lokale Chrome extensie die exact deed wat ik wilde.
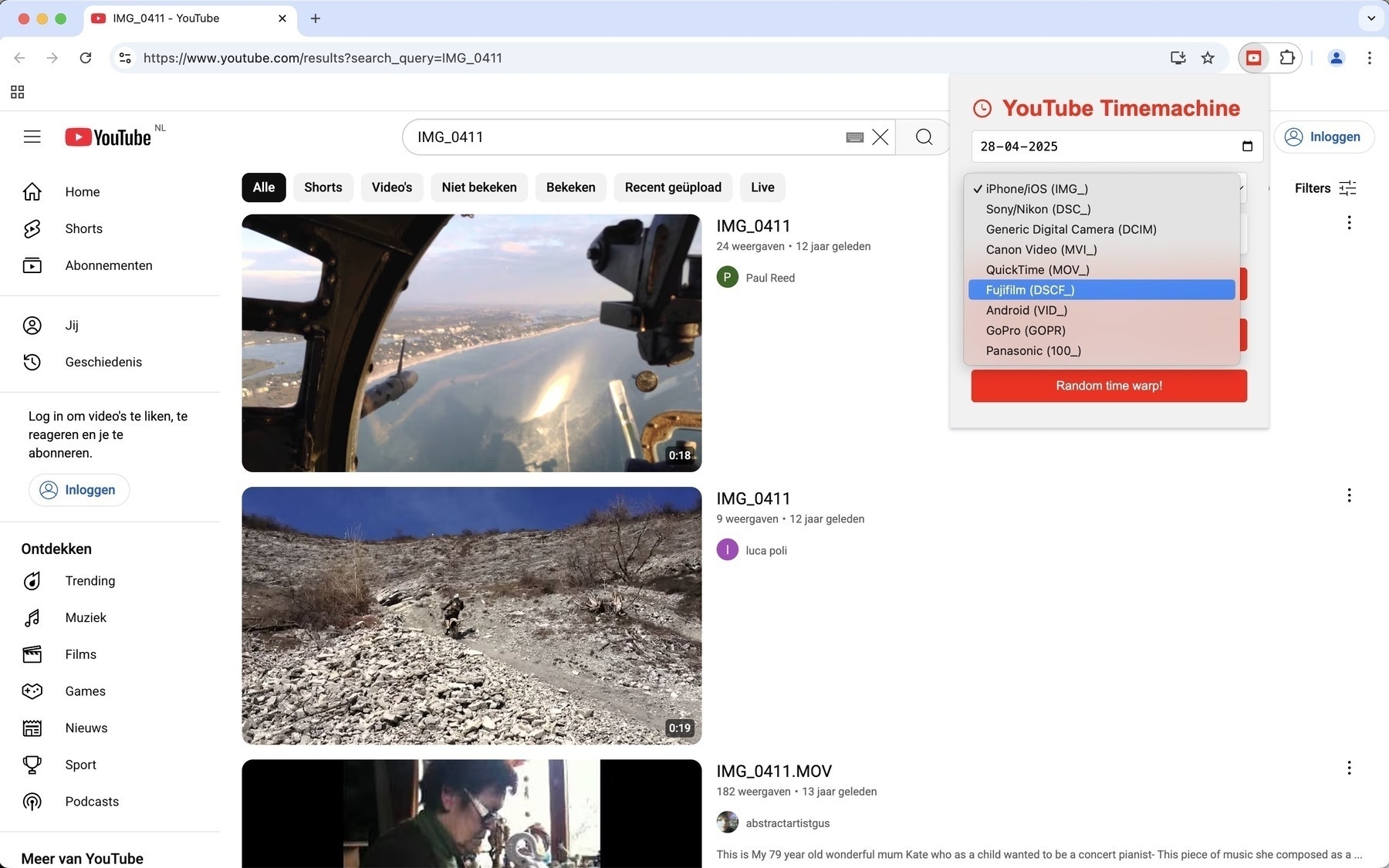
Je kiest een datum en een cameramodel. Van de maand en de dag maakt de code vier getallen. Zo zou vandaag 0501 zijn en plakt deze met het gekozen model in een zoekopdracht voor Youtube. Om vervolgens in Youtube direct de resultaten te laten zien. Hier zie je video’s met de titel DSC_0501 of hier zie je video’s die met een Go Pro zijn gemaakt en de bestandsnaam GOPR1127 hebben. Je kunt ook een random model en getal selecteren met de Timewarp knop. Ik koos er voor om een datum als startpunt te maken om de vier getallen te genereren. De extensie zoekt dus niet naar video’s die met de specifieke modellen op de specifieke datum zijn geplaatst. Is dat te onduidelijk nu? Laat het me weten.
De resultaten zijn net zo verrassend als in het artikel van Germain. Er komen dashcams voorbij met 15 views, een jonge skier met 2 views of een voorstelling van drie jonge vriendinnen, slechts één keer bekeken. De rustgevende watervallen van Allagash, Maine. Sommige video’s zijn nog nooit bekeken als je door de lijst scrollt, sommigen hebben al honderden views. Maar het zijn vrijwel allemaal video’s die vrij zijn van call to actions, “like en subscribe” iconen en gelikte producties. Het zijn doorkijkjes in het dagelijkse leven van mensen overal ter wereld. Het zijn video’s die niet de pretentie hebben dat de maker een influencer wil zijn op social media. Het zijn persoonlijke boodschappen waarbij de maker de middelen gebruikt die voor handen zijn. Zoals snel een video maken, uploaden en privé delen.
Youtube noemt zich graag het epicentrum van populaire cultuur en het nieuwe Hollywood. Ik zie het liever als publieke infrastructuur voor mensen die een verhaal willen vertellen. Ongeacht voor hoeveel kijkers dat is.
Hoe maak je een browser extensie?
Ik had nog nooit een browser extensie gemaakt, dus ik liet Deepseek me eerst maar eens uitleggen hoe die in elkaar zitten. Vervolgens is het model aan de slag gegaan om de extensie te maken, en op basis van mijn aanwijzingen constant wat aanpassingen te doen. Tenslotte heeft AI me geholpen met de uitleg hoe ik een browser extensie kan publiceren op de Chrome Web Store en bij Mozilla Add Ons.
Alles zit relatief eenvoudig in elkaar. Je kunt de volledige code op Github vinden, downloaden en zelf aanpassen.
Met de hulp van AI kon ik van een idee naar livegang gaan in nog geen 90 minuten. De meeste tijd zat in het maken van de juiste iconen en het invullen van de formulieren bij Mozilla en Google om de extensie te publiceren. Al het basiswerk is door AI gedaan. Ik heb zelf nog wel de code bekeken. Omdat het relatief eenvoudig in elkaar zit, kan ik het wel beoordelen of het doet wat het moet doen. Mogelijk kunnen wat functies efficienter en zal de CSS meer gestroomlijnd kunnen. Maar ik ben er voor nu tevreden mee.
Ik ga nu nog uitzoeken waar en hoe ik de extensie het beste kan promoten. Ik vermoed sowieso op een aantal specifieke subreddits en op Hacker News. Natuurlijk mail ik de auteur van het artikel, ik denk dat hij er ook wel interesse in heeft. Mogelijk kan ik Ethan Zuckerman nog een bericht sturen. Ik wil er niet héél veel tijd aan besteden, het is vooral een leuk probeersel om iets bij te dragen aan het internet dat we wel eens vergeten in de comerciele bombarie die we over ons heen krijgen. Het internet van de kleine, persoonlijke interacties. Waar je even een video upload om aan iemand te laten zien. Niet met de bedoeling om er rijk mee te worden of veel invloed mee uit te oefenen. Maar om wat te delen. Als ik dat meer zichtbaar kan maken met deze browser extensie, dan is mijn doel gehaald.
Ook leuk om te weten, ik publiceerde ooit de 150e video ooit op Youtube. Die korte minispeedway video van 20 jaar geleden is slechts door 5.500 mensen bekeken. Het is iets meer ge-edit en geen standaard camera-bestandsnaam, maar toch een stukje verborgen Youtube historie…
AI na 2025 - Solarpunk versus cyberpunk
Vanavond zag ik twee TED talks. Allereerst de digitale noodklok van Carole Cadwalladr. De journaliste waarschuwde in 2019 op hetzelfde podium voor de groeiende en ongebreidelde macht van BigTech, wat leidde tot rechtszaken die haar leven en werk bedreigden. Nu is ze terug, strijdlustig. En angstig. Voor wat komen gaat als ze nu weer de lijnen verbindt. De lijnen tussen de geopolitieke macht en de AI-techreuzen die zich nestelen in het centrum van de politiek. Haar verhaal is 17 minuten luisteren naar een oproep voor digitale ongehoorzaamheid, voor een publiek dat zichtbaar ongemakkelijker wordt door haar boodschap.
Daarna keek ik de fireside chat tussen TED directeur Chris Anderson en OpenAI CEO Sam Altman. Een minstens zo ongemakkelijk gesprek, omdat Anderson Altman verleidt meer te vertellen over zijn ethische en morele roadmap. Iets waar Altman deels in mee gaat, waar je merkt dat hij soms echt even na moet denken wat hij op welke manier zegt. Ik vraag me af of Altman anders op het podium zou zitten als Cadwalladr niet een dag eerder haar uitspraken op hetzelfde podium had gedaan. En hem direct aansprak. Ik kreeg het idee dat hij zich nu wat terughoudend opstelde. Veel van zijn uitspraken zijn in de trant “het zou anders moeten” en “wat we nodig hebben”, zonder daar al te veel eigen invulling aan te geven. Want daarmee legt hij de toekomst van OpenAI vast. Hij lijkt zich in te dekken dat hij het wel anders zou willen, maar dat het niet aan hem zal liggen als het toch anders loopt.
Hij kan bedachtzaam zijn en op het podium balanceren tussen fascinatie van de innovatie en de maatschappelijke implicaties. Ondertussen is hij onderdeel van de broligarchy en rolt hij open en bloot een systeem uit in OpenAI dat nu alle herinneringen en gesprekken die we hebben met de AI kan gebruiken voor toekomstige gesprekken. Het Stasi-gebouw van Cadwalladr wordt op klaarlichte dag onder onze neuzen gebouwd.
Ik hou van de technologie die OpenAI en anderen ontwikkelen en wat het mogelijk kan maken. Het fascineert me mateloos, net als het World Wide Web me 30 jaar geleden op het pad bracht waar ik nu ben. Maar tegelijkertijd zijn de gevaren en de implicaties torenhoog en overduidelijk. Zoals Cadwalladr zegt, “Politics is technology now”. Elke nieuwe innovatie kun je niet meer zien zonder de grote politieke en maatschappelijke veranderingen die het met zich meebrengt. Zoals Altman zelf zijn verhaal afsluit, als onze (klein-)kinderen in een wereld opgroeien, waar de door mensen gemaakte omgeving vele malen slimmer is dan zij zelf, door AI, wat voor wereld is dat dan? Hoe kunnen we veranderen van een dystopische cyberpunk naar een utopische solarpunk?
Ik heb de organisatie SETUP en onderzoeker Siri Beerends hoog zitten. Maar haar stuk “Waarom we de AI boot prima kunnen missen” gaat wel érg kort door de bocht. Omdat er willekeurige “lollige” plaatjes worden gegenereerd, omdat nu al uit wetenschappelijk onderzoek blijkt dat het schadelijk is, en zo worden er nog meer gevestigde tegenargumenten op een rij gezet. Kritiek op technische ontwikkelingen is goed en nodig. Ik zal de laatste zijn om er hoongelach op los te laten. Maar ik zoek zelf wat meer de nuance op. Wat kan er wél goed gaan. Wat kan wél met deze nieuwe technologie. Daarover later nog wel meer. Die gedachten moet ik echt eens rustig op een rij zetten.
The day the internet woke up
The Day the Internet Woke Up. Een technicolor feverdream-glitch die zich over je heen stort op het moment dat de singulariteit zich manifesteert via een AI gedreven…iets. Dystopische Media Kunst, gemaakt door Antibody.tv.

Tag je teksten met AI
Een fijne zondagochtend rabbit-hole. Martijn Aslander bracht me op het spoor van Jorge Arango en zijn boek Duly Noted. Daar begin ik binnenkort aan, maar ik was nu vooral geïntrigeerd door zijn gebruik van AI om posts van zijn eigen blogs beter te taggen. Jorge heeft een uitgebreide handleiding gepost. Niet voor de absolute beginner en je moet niet bang zijn om zelf wat te sleutelen en te klooien. Maar je kent me…
Een deel van mijn oudere posts uit 2023 liggen nu op de testbank, waar ik een AI model de posts laat lezen en voorstellen doet voor nieuwe tags. Die tags komen uit een vooraf opgestelde lijst. De volgende stap is dan het controleren van de lijst, zien of het model toch zelf tags verzint en bepalen hoeveel ik handmatig nog moet aanpassen. Ik kan zo met terugwerkende kracht mijn blogposts beter vindbaar maken én beter aan elkaar gelinkt. Dit kun je met je blog doen, maar omdat het hier om lokale tekstbestanden gaat, zou ik dit ook prima met mijn PKM systeem kunnen doen. De belangrijkste voorwaarde is dan wel dat ik een lokaal model gebruik, zodat mijn notities niet in een databank bij een grote AI provider staan. En laat dat nou prima mogelijk zijn met de huidige hardware die ik heb, of met hyperlokale servers waar je zelf meer controle over hebt dan de grote modellen die claimen als Zwitsers zakmes voor alles een oplossing te zijn.
Het is nu mogelijk om Deep Research te gebruiken in ChatGPT. Waar je eerst een maandabonnement van $200 nodig had, kun je nu met het $20 abonnement 10 queries per maand doen. Ik zie het als een interessante manier om een LLM schaduw te laten draaien op strategisch en marktonderzoek dat we doen bij Kaliber. Vooral om te zien wat de resultaten zijn en hoe ze zijn te interpreteren. Ik geloof er nog niet in dat Deep Research volledig zelfstandig is in te zetten, want de resultaten zijn nog altijd niet te vertrouwen. Zo laat Benedict Evans zien aan de hand van zijn eigen kennisgebied, smartphones.
LLMs are not databases: they do not do precise, deterministic, predictable data retrieval, and it’s irrelevant to test them as though they could. But that’s not quite what we’re trying to do here - this is a rather more complex and interesting test.
Benedict koppelt de belofte van LLM’s en onderzoek wel aan een befaamde quote van Steve Jobs
[…] these things are useful. If someone asks you to produce a 20 page report on a topic where you have deep domain expertise, but you don’t already have 20 pages sitting in a folder somewhere, then this would turn a couple of days’ work into a couple of hours, and you can fix all the mistakes. I always call AI ‘infinite interns’, and there are a lot of teachable moments in what I’ve just written for any intern, but there’s also Steve Jobs’ line that a computer is ‘a bicycle for the mind’ - it lets you go further and faster for much less effort, but it can’t go anywhere by itself.
Hier zit de belofte van mens-machine interactie. Een machine alleen kan niet alles wat we verwachten als mens dat een machine zou kunnen. Zeker niet als het om LLM’s gaat. Maar de machine kan je, mits goed geïnstrueerd, wel verder helpen in je denken. Nieuwe wegen vinden, andere denkpatronen. Kritische AI geletterdheid is een essentiële volgende stap. En dat terwijl de digitale geletterdheid vaak nog op een laag niveau is.
Zie ook “Met je familie draken verslaan” als voorbeeld.
Samenvattingen bij blogposts
Sinds mijn verhuizing van zelf-geïnstalleerde en -onderhouden WordPress naar hier-heb-je-geld-regel-het Micro.blog hosting, ben ik best tevreden over de laatstgenoemde service. Het is gewoon heel eenvoudig. Ik schrijf, ik publiceer, ik ga verder. Ik hoef me niet per sé bezig te houden met nieuwe functionaliteiten, met updates, met gedoe. Want eerlijk is eerlijk, WordPress was best wel vaak gedoe. Of eigenlijk, het uitgangspunt dat ik alles in eigen beheer had, leidde er toe dat ik van alles bedacht omdat het kon. Niet dat het altijd zo handig was om te maken of te onderhouden.
Maar goed. Ik ben dus blij met Micro.blog. Niet in de minste plaats omdat eigenaar/helpdesk/programmeur/man-met-mening Manton in een constant tempo vernieuwingen en updates doorvoert. Zo is het nu mogelijk om samenvattingen van een post te maken. Dat klinkt voor menig WordPress-adept als een “pffffff…gast! Dat kunnen we al jáááren!” en dat klopt. Ik maakte er soms wel eens gebruik van. Zeker bij langere posts is het handig om een samenvatting in een feed of social post aan te bieden. Je schrijft de samenvatting zelf, maar zoals Manton het in bovenstaande link zegt, je kunt het ook door AI laten genereren. Mja, zou kunnen. Als ik gebruik maak van de web-interface van Micro.blog. Maar dat doe ik niet. Vrijwel al mijn posts zijn geschreven in Drafts of Obsidian, via een koppeling met de Micro.blog API. Ik gebruik plugin voor Drafts en plugin voor Obsidian. Nu is het dus wachten tot deze plugins updates hebben waarmee ik eventuele samenvattingen kan toevoegen aan langere posts.
Want no way dat ik zelf die plugins ga aanpassen omdat ik niet kan wachten… toch? Tóch?
PS: Om het effect van de samenvatting wel te zien, heb ik voor deze ene keer de post geschreven in Drafts, maar daarna gepubliceerd via de officiële webinterface. Vooruit dan. En de samenvatting via AI is gewoon slecht. Sorry Manton.
Stichting Brein en 1984
De laatste weken is AI-land in rep en roer over Deepseek, het Chinese model dat volgens de overlevering met minder geld meer gedaan krijgt. Je moet wel op de koop toe nemen dat de online versie het niet zo nauw neemt met jouw gegevens, maar er is een offline en open source model. Daarmee kun je je eigen versie van Deepseek gebruiken, zonder dat de Chinese overheid meekijkt.
Ik vroeg de online versie naar moderne voorbeelden die geïnspireerd zijn op The Ministry of Truth, uit de klassieker 1984. Je raadt nooit hoe Deepseek daar mee om ging…
Dus iedereen aan de open source, lokale modellen? Niet zo snel… Kijk eens wat gebeurde met het Nederlandse taalmodel GEITje van Edwin Rijgersberg. Een succesvol open source project om een Nederlands taalmodel te ontwikkelen. Een LLM dat werd gebruikt door hobbyisten en wetenschappers. Helaas steekt Stichting Brein (weer) een stokje voor verder ontwikkeling en moet Rijgersberg het model offline halen. In het persbericht van de Stichting:
BREIN heeft de aanbieder o.m. aangesproken omdat het model getraind was op tienduizenden kopieën van Nederlandstalige boeken uit illegale bron.
Natuurlijk zijn er genoeg kopieën van GEITje in omloop, aangezien je het model kon downloaden en lokaal gebruiken. Dus het is niet écht offline. Maar het gaat hier (weer) om de auteursrechten discussie. Zoals Brein die in de muziekindustrie gebruikte om P2P delen de kop in te drukken. Maar goed, terwijl China en de Verenigde Staten lekker doorontwikkelen, zien we hier in Europa al weer een vertraging ontstaan door dit soort praktijken. Het is alles of niets volgens Stichting Brein. Je gebruikt auteursrechtelijk materiaal dus alles moet offline. Terwijl je volgens mij je tijd beter kunt besteden aan het afstemmen van de juiste vergoedingen en het eenvoudiger maken van de afhandeling.
De discussie is complex en ik ben er zelf ook nog altijd niet uit, wat nu dé weg is. Enerzijds ben ik verschrikkelijk enthousiast over AI en de achtbaan van innovatie die nu plaatsvindt, anderzijds geloof ik in een maatschappij waar kennis open en zonder restricties moet rondwaren, open source en bereikbaar. Maar zonder daar voorbij te gaan aan ethische, sociale en maatschappelijke normen. Zoals vergoedingen, beschikbaarheid, energieverbruik en privacy.